The evolution of Industry 4.0 is not linear. It’s exponential. Data is no longer just a byproduct of design. The fusion of the two disciplines is fuel for innovation and quality. For this reason, it’s rare for the cost of a data management strategy to outweigh the benefits. If your company has a small and finite product offering with no plans for growth, it might not be for you. If that isn’t you, rest assured, the business case for data management in your organization is strong.
Data management has transcended its corporate key-phrase status. As that awareness grows, so does the need to adopt a data management strategy to secure and expand your market share. Data has value that can be maximized, just like products. When companies begin to manage their data and harness that value, they never turn back.
What is it?
Data management is an entire field of data science with its very own International Association (DAMA) that breaks the definition down into 11 disciplines (not covered here), including data governance. At its core, data management is about collecting, storing, and using information related to your product. But it’s not the definition that makes it interesting, transformational, or powerful – it’s what it can do.
So how does a data management strategy transform your data framework’s diminishing returns into an investment in your future? Here we break it down into three pillars, supporting the continuous improvement of business worldwide:
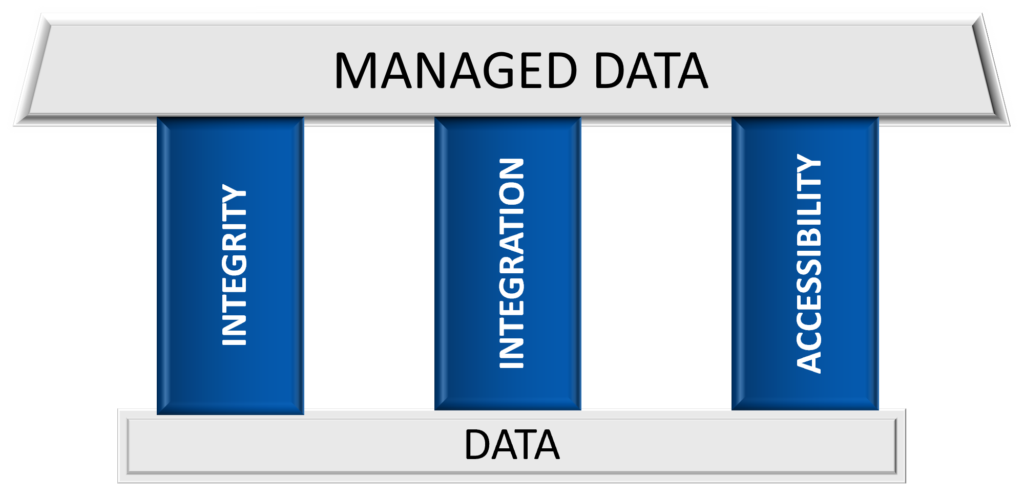
What does it do?
Pillar I: Data Integrity
Information is an asset. Misinformation is a liability.
Misinformation is a byproduct of data ambiguity, duplication, and hoarding. In the wild, misinformation is rampant. Ungoverned, it can devolve into separate versions of the truth that chip away at profits. It throttles efficiency and causes production errors responsible for reordering, back ordering, rework, and extended lead times. Governed product data drives profits by increasing productivity and reducing errors. As the quality of the data improves, so does the profitability of your product.
So, misinformation is commonplace in business. Got it. But how do we stop it?
To stop it, we treat problems rather than symptoms. Even though you can create a banging corrective action procedure with your data management solution, that won’t solve data integrity problems. Instead, data is cleansed and aligned to avoid mistakes needing correction.
Causes of Siloed Data
Poor data integrity is the result of data silos. Data silos develop when organizational silos create overlapping data sets unilaterally. Consistent quality data results from homogenizing standards and practices. No more overlapping data sets to translate. Just one validated set of data under the stewardship of all who contribute to it. Data management adoption leads to cultural adoption. As data silos fall, organizational silos follow because everyone (with the requisite permissions) has ownership of the same data.
Through disambiguation and deduplication, the entire data value chain is streamlined. Better data goes in, and better products come out. Plus, you’ll save on some file storage.
Data Value Chain

Pillar II: Integration
Your data management solution can and should integrate business systems and processes to create a clear line of sight to a holistic, unified view of your data. When data is warehoused in disparate systems, the data pipeline is innately bottlenecked. If the application warehousing this data is intelligent enough, it can obsolete other systems, unifying the data by consolidating your application pool.
Otherwise, it can integrate with the other applications through an Application Programming Interface (API), middleware, or by parsing flat files (like CSV or XML). Using an ETL process (Extract, Transform, Load), information can be translated from its original form to match the conventions of the destination system. Both systems coexist, blissfully ignorant of their intrinsic differences.
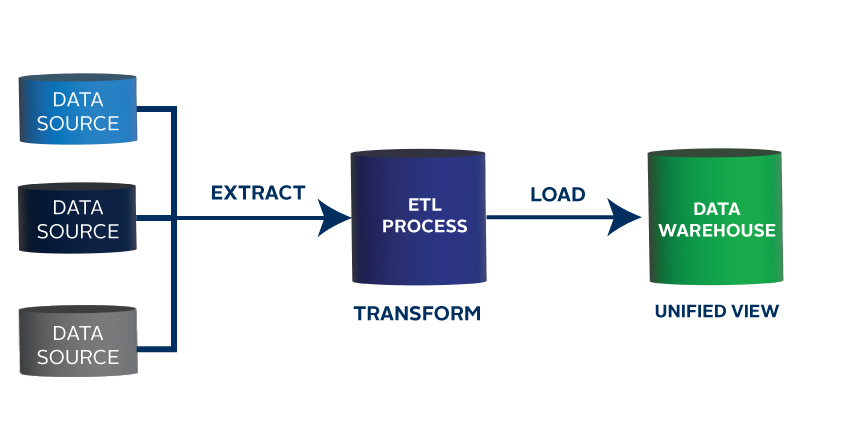
Whether your data’s ecosystem is entirely self-contained or a collection of interfacing subsystems, its lifecycle can be chronicled and automated, removing bottlenecks along with the potential for human error (or defiance) inherent to manual touchpoints. Processes become leaner, and their outputs become more accurate. Phone calls, meetings, and emails are replaced with intelligent real-time system notifications, which greatly enhance collaboration and optimize resource utilization.
Pillar III: Accessibility
At some point, corners get cut, and shortcuts are taken. It may not have been obvious or even foreseeable at the time, but the network that was built to house your once juvenile dataset inevitably teeters like a house of cards under the mounting gigs and complexity of your intellectual property. It happens to everyone at least once. If you’ve read this far, there is a good chance it’s happening to you. Unmitigated, this will inhibit business growth while bit rot and tech debt take over. More likely, both.
Fortunately, the mitigation strategy is fairly simple, and the rewards are immense. Data is useless unless it can be consumed. A complex dataset can be hard to navigate and even harder to understand. When the right data can’t be found or understood, its would-be consumers go rogue, introducing the ambiguous and duplicate data you read about earlier.
In any data management system, searchability is key to success. All information needs to be searchable, directly and indirectly, to support design reuse, metrics, KPIs, and continuous improvement. Access to data generates business intelligence that leads to data-driven business decisions and outcomes that would be impossible without the data transparency afforded by a data management solution. This transparency is paramount to making your evolving data set synergistic and powerful. But, with great power comes great responsibility.
The phrase “Data transparency” can cause CIOs and their ilk to twitch due to the connotation that it’s the polar opposite of data hoarding – a free for all. It’s not. Data transparency is about accessibility, but visibility is granted selectively, and dissemination happens pragmatically. We are talking about data governance, after all. In the pantheon of all your enterprise data are nooks and crannies that not everyone needs, or even wants, access to. Privacy and security measures are integral components of data management systems, necessary to thwart information overload, data misuse, or misappropriation.
Newly equipped users with access to all the data all the time can backfire. When brandishing a shiny new hammer, everything can begin to look like a nail. Still, internal data needs to stay internal, and work in progress must stay off the shop floor. On the flip side, other users may feel lost when first exploring oceans of metadata, souring the taste and hindering your efforts to garner user acceptance. It’s about getting the right information into the right hands at the right time, every time.
What’s Next?
If this super-abridged pocket guide to what data management is left you eager for more, you’ll want to watch our on-demand webinar on Data Management Made Easy and read our blog Do I Need Data Management? – The Business Case, to understand why you need it, how to build your business case, and what implementation looks like. Stay tuned.
Contact Us
If you are interested in learning more about how to empower your data to drive your success, contact us and explore our data management solutions further here.
Share
Meet the Author
view all posts by Chris Fortin
SOLIDWORKS Webinars & Power Hours
